基于META自动后处理:
Python二次开发在整车NVH分析后处理中的应用
Python二次开发在NVH分析VTF、NTF后处理中的应用
上面的后处理过程都是基于商业软件进行的,很多数据加工的功能受限于软件的函数接口,因此不够丰富。同时,基于hypergraph或meta的后处理都需要启动软件来完成数据处理,如果进行优化集成则(后台)启动后处理软件也需要一些时间。
这里介绍一些基于Python的CAE结果后处理方法,而不是基于商业软件来完成。包括Nastran结果文件.op2和.pch,LSDYNA结果文件d3plot和binout等自动后处理过程。ABAQUS的开发语言支持Python,因此对于ABAQUS的.odb结果自动后处理就不做过多的介绍。这些自动后处理过程既可用于常规分析自动后处理,也可以用于多学科优化时优化流程的集成,且这些过程不需要商业软件,只需要简单的配置下Python环境即可。
本文介绍基于Python的Nastran结果文件.pch自动后处理,包括IPI、VTF等。一、IPI自动后处理
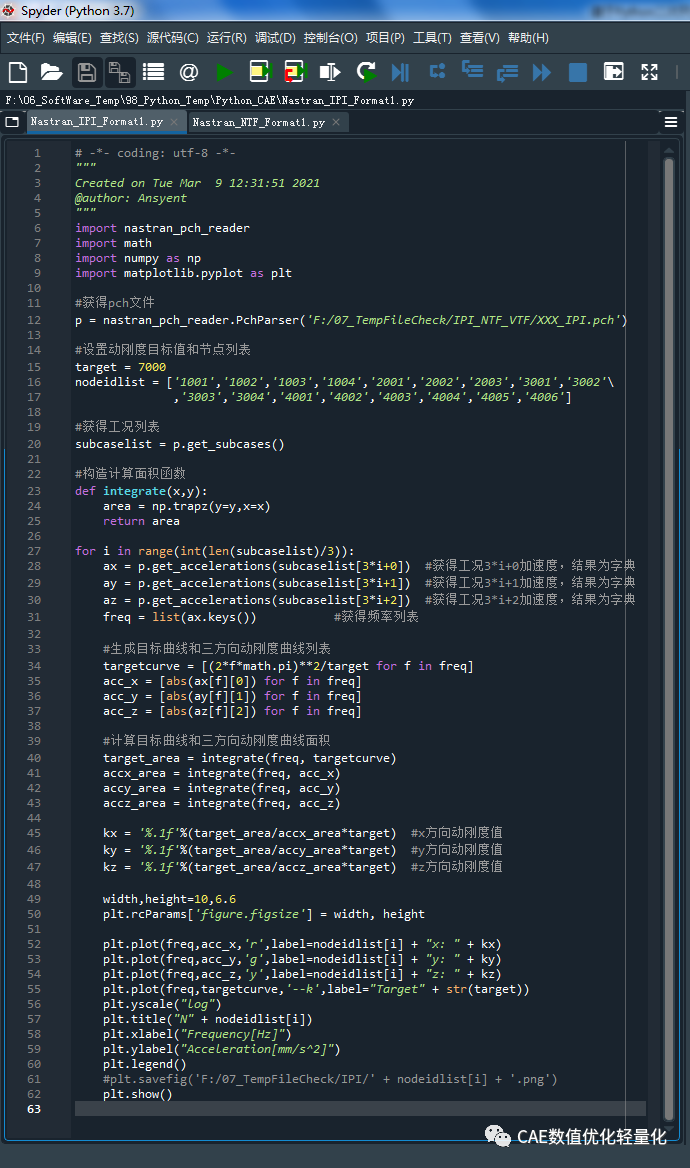

这里定义了一个计算曲线面积的函数,用于后续动刚度计

其中ax、ay、az是通过get_accelerations函数得到的一个包含所有分析输出频率个数的字典,字典的键为频率,值为包含六个方向的加速度值,即三个平动三个转动加速度值的列表。并且是通过实部虚部给出的,我们要的是幅值和相位表达,因此后续需要通过abs函数求出对应的幅值。
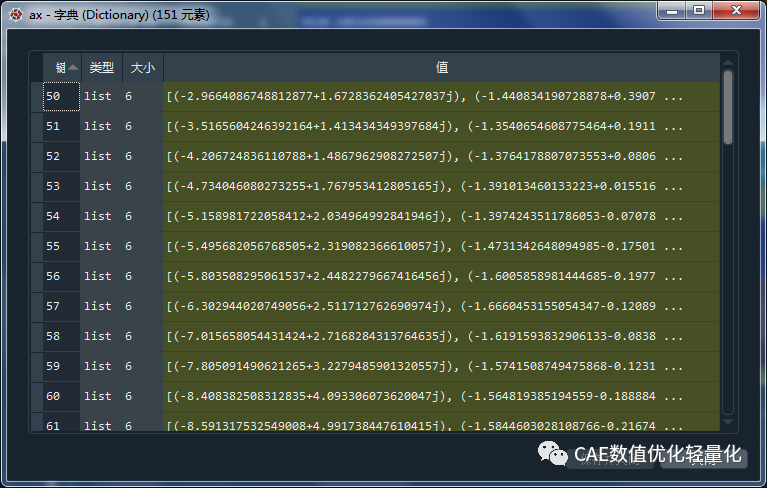
在spyder环境下运行的效果。
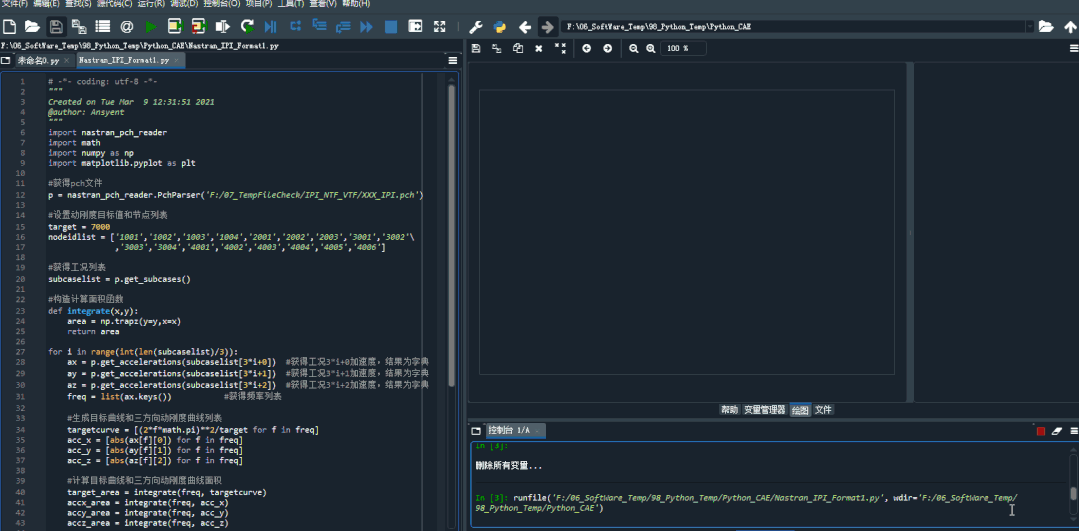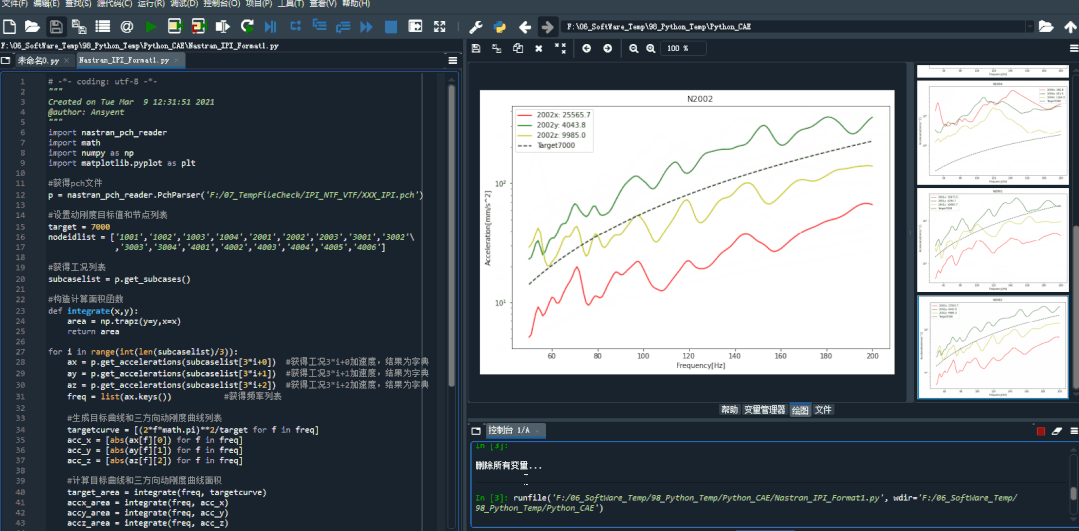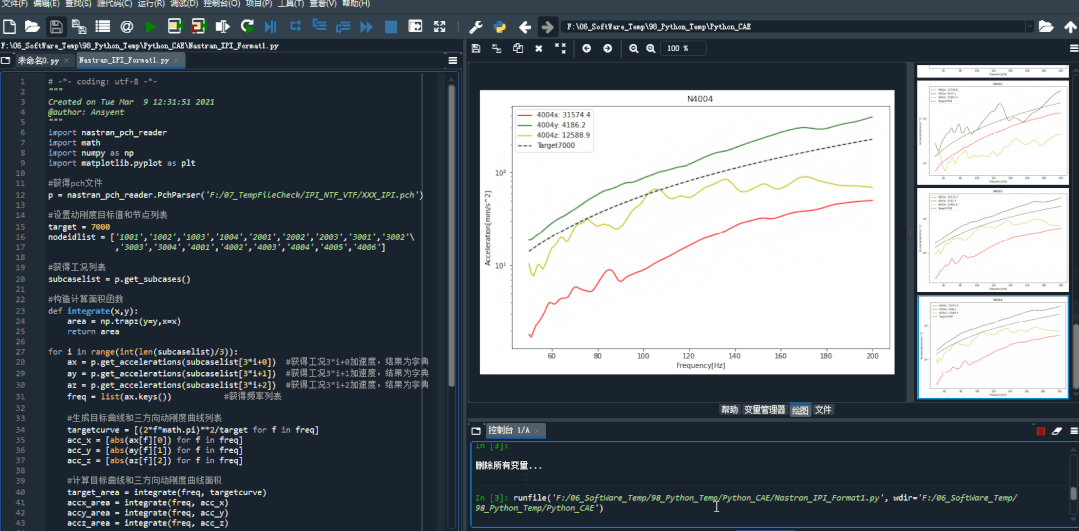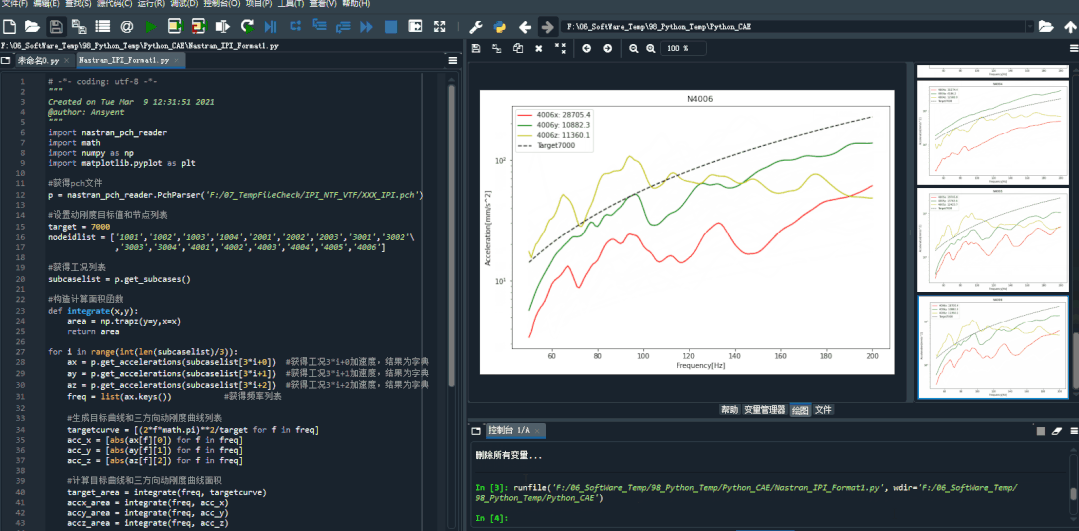
结果图片:
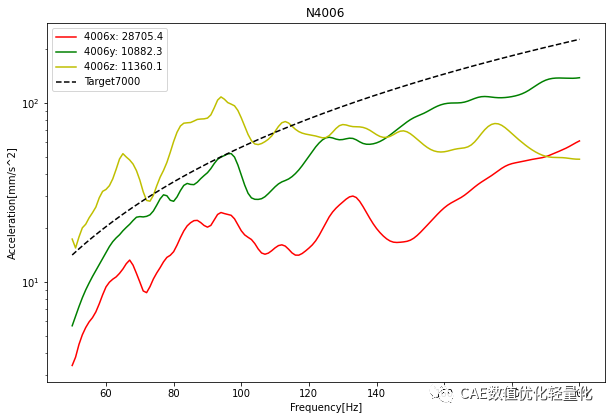
二、VTF自动后处理
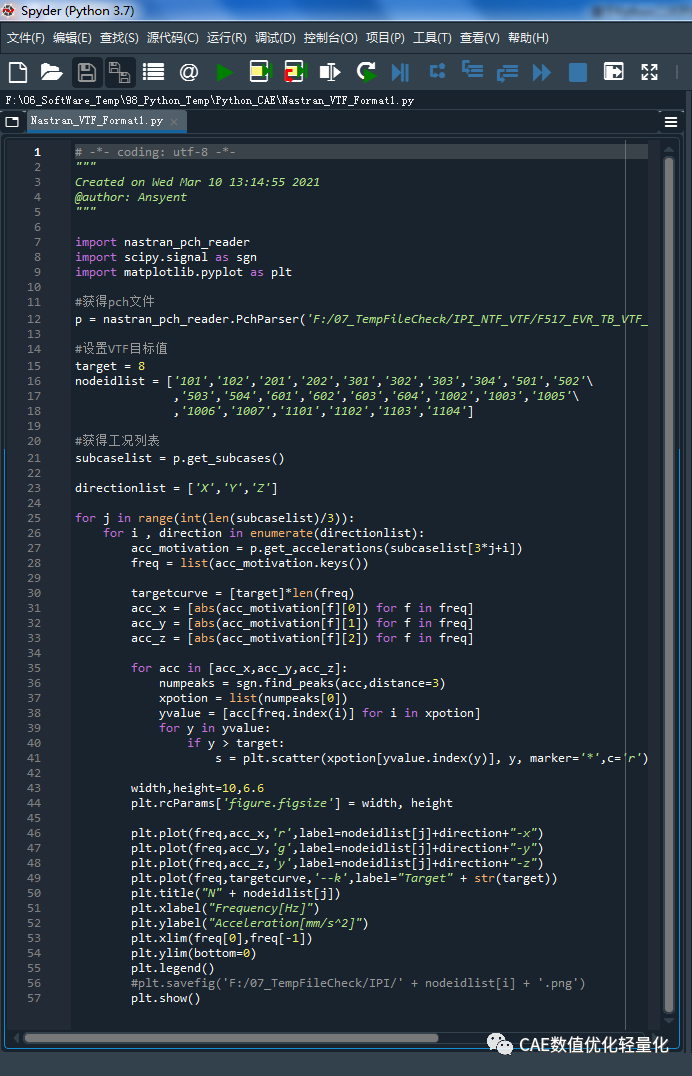



这里通过scipy中的find_peaks函数找到不满足目标值的局部极值点,并在图中用红色的*号标记出来。

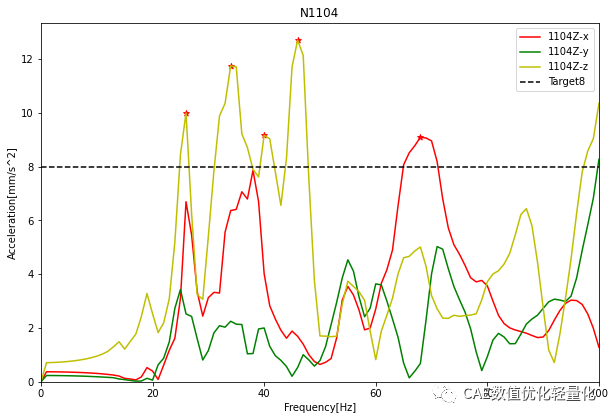
(注:这里只是为了演示,因此把目标值设置为8)。
以上只是简单介绍了.pch文件的读取和结果自动后处理过程,整个过程只需要几行Python代码即可完成。运行时间也就几秒钟。而不需要在商业软件中来进行。如果是进行优化集成,则不要输出结果图片等信息,只需要输出结果响应即可,会大大提高效率。同时,如果需要自动生成报告和结果统计等,只需要在次基础上添加简单的几行命令即可,十分方便简洁。
